
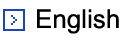
機械学習
研究室では、機械学習や深層学習の基礎的な理論やモデル開発も重要な課題として取り組んでいます。 ただし、私たちの興味は実用的な知能システムの実現にあり、機械学習はあくまでそのための道具の一つとして使っているという立場です。 機械学習や理論ありきの研究にはならないよう、現実世界の問題に対してなぜそれが必要なのかを常に問いながら研究を進めています。
ニューロシンボリックAI
深層学習は強力な道具であることは間違いありませんが、何でもデータからの学習を行うことが合理的であるとは限りません。場合によっては、古典的な人工知能が用いていたルールや知識に基づく方法が遥かにうまく働くこともあります。 機械学習がとる帰納的なアプローチと、ルールや知識ベースによる演繹的なアプローチの融合は、人工知能を次の段階へ進めるために重要な課題であると考えられていますが、 後者は往々にして離散的な構造を持つため、単純にニューラルネットワークの勾配法による学習に組み入れることは困難です。
研究室では、ルールに基づく離散的なモジュールをニューラルネットワークに組み込みながら、全体としてend-to-endに学習するための枠組みの開発を行っています。 また、モジュール内で外部の知識グラフを探索させることで、整理された知識をトップダウンに与える試みも行っています。
- Vo et al., "A-CAP: Anticipation Captioning with Commonsense Knowledge", IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.10824-10833, 2023. pdf
- Yuxuan Wu and Hideki Nakayama, "Weakly Supervised Formula Learner for Solving Mathematical Problems", Proceedings of the International Conference on Computational Linguistics (COLING), pp.1743–1752, 2022. pdf
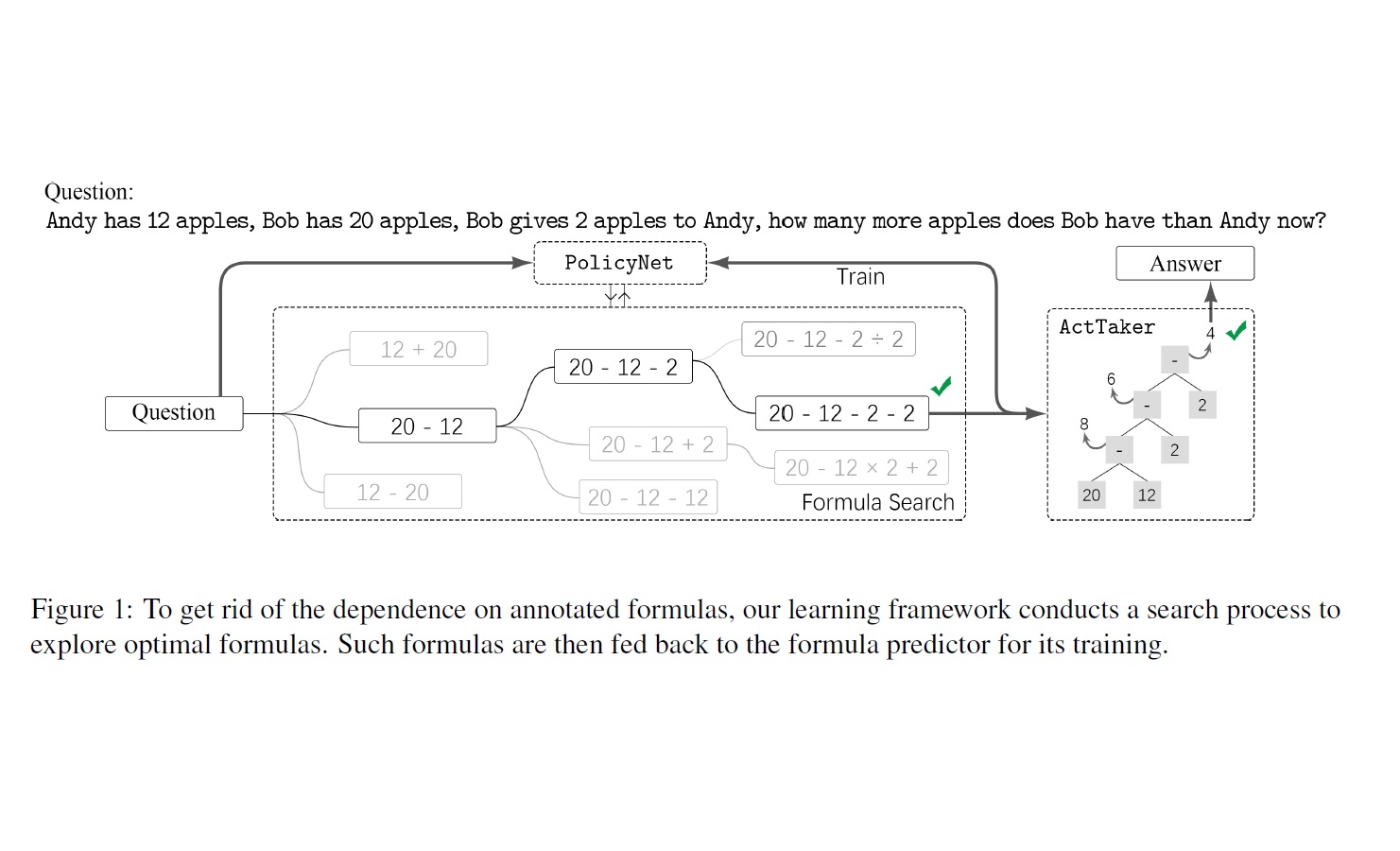
- Hong Chen et al., "Commonsense Knowledge Aware Concept Selection for Diverse and Informative Visual Storytelling", Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI), pp.999-1008, 2021. pdf
- Yuxuan Wu and Hideki Nakayama, "Graph-based Heuristic Search for Module Selection Procedure in Neural Module Network", Proceedings of the Asian Conference on Computer Vision (ACCV), pp.560-575, 2020. pdf
信頼できるAI
深層学習の大きな問題点として、その推論過程や内部表現がブラックボックスであることが挙げられます。例えば、基本的な画像認識ネットワークを用いた場合、入力画像の認識結果について、なぜそのように判断されたのかは誰にも分かりません。 また、大規模な基盤モデルでは、学習に用いたwebデータに起因する不適切なバイアス(差別的傾向など)があることも指摘されています。 AIが誤りや不適切な挙動を起こした場合に、その理由や根拠を可視化できなければ改善も困難であるため、AIが実社会で真に信頼されるようになるのは難しいでしょう。
我々は、深層学習のモデルに内在するバイアスの可視化・是正を行う研究や、認識時の根拠を可視化する研究など、さまざまな観点から信頼できるAIの実現へ向けた試みを進めています。
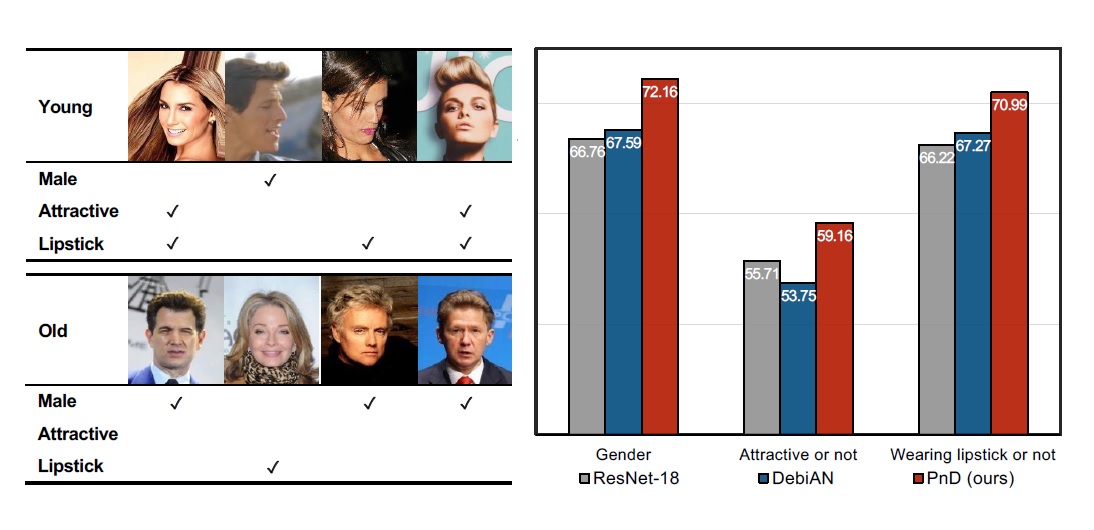
- Jiaxuan Li, Duc Minh Vo, and Hideki Nakayama, "Partition-and-Debias: Agnostic Biases Mitigation via a Mixture of Biases-Specific Experts", Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023.
- Taiga Kashima, Ryuichiro Hataya, and Hideki Nakayama, "Visualizing Association in Exemplar-based Classification", Proceedings of the 46th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp.1780-1784, 2021.
データ拡張
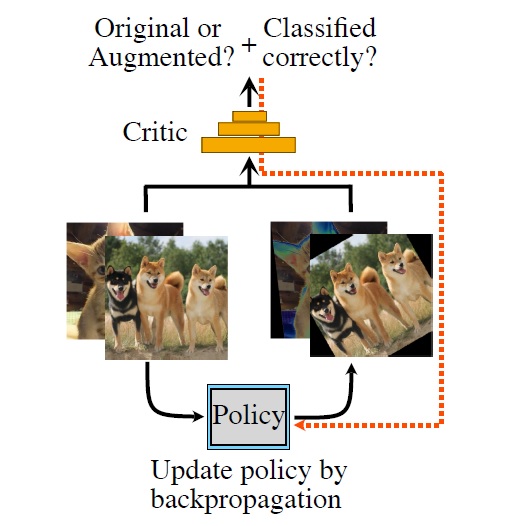
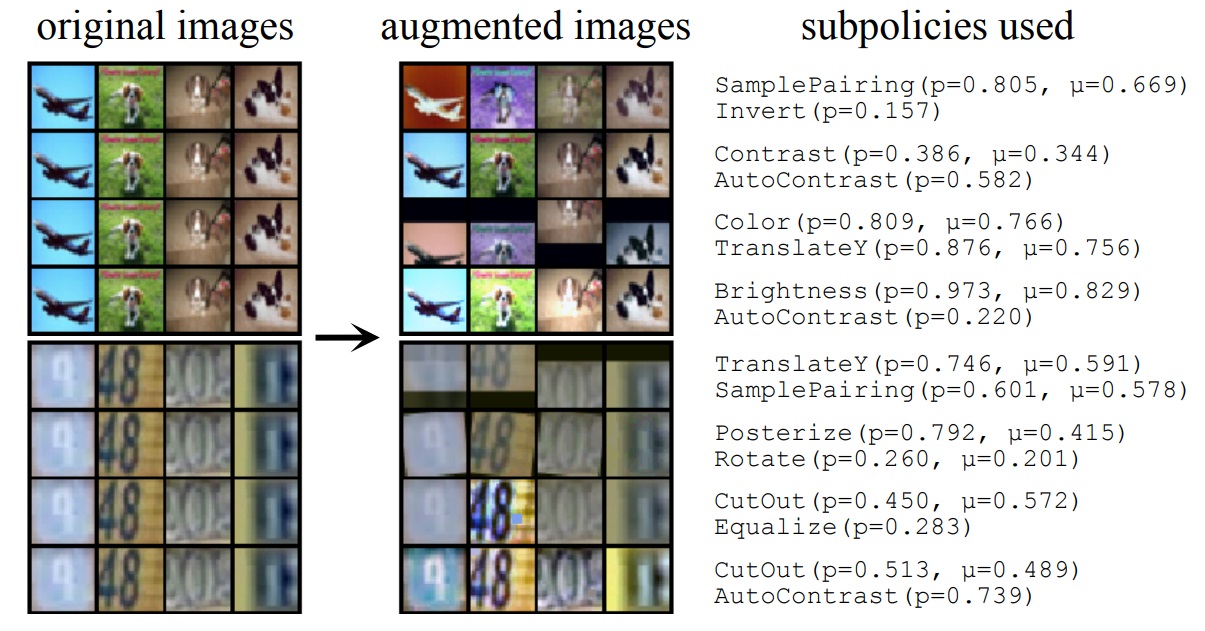
データ拡張は、タスクに対する先験的知識を活用して人工的に訓練データを生成する操作であり、深層学習の性能向上を行うために鍵となる技術の一つです。 研究室は、主に二つのアプローチからデータ拡張の研究に取り組んできました。第一のアプローチは、既存データの変換によって新たなデータを作るものであり、特に画像認識において古くから成功してきました。 ここでは、画像の反転・拡大縮小・回転などの基本的な変換を適切に行うことが重要になりますが、我々はそのような変換操作を微分可能探索法により高速に最適化する手法を研究しています。 第二のアプローチは、GANなどの生成モデルによって直接的に新たなデータを作るものです。我々は、医用画像認識や文字認識を題材としてGANによるデータ拡張手法を複数開発しており、その有効性を実証しています。(画像・動画像生成を参照)
- Ryuichiro Hataya et al., "Meta Approach to Data Augmentation Optimization", Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), pp.2574-2583, 2022. pdf
- Ryuichiro Hataya and Hideki Nakayama, "DJMix: Unsupervised Task-agnostic Image Augmentation for Improving Robustness of Convolutional Neural Networks", International Joint Conference on Neural Networks (IJCNN), 2022.
- Jan Zdenek and Hideki Nakayama, "JokerGAN: Memory-Efficient Model for Handwritten Text Generation with Text Line Awareness", Proceedings of the 29th ACM International Conference on Multimedia (ACMMM), pp.5655-5663, 2021. pdf
- Ryuichiro Hataya et al., "Faster AutoAugment: Learning Augmentation Strategies using Backpropagation", Proceedings of the 16th European Conference on Computer Vision (ECCV), 2020. pdf
- Ryosuke Kuwabara et al., "Single Model Ensemble using Pseudo-Tags and Distinct Vectors", Proceedings of the 58th annual meeting of the Association for Computational Linguistics (ACL), pp.3006-3013, 2020. pdf
- Changhee Han et al., "Learning More with Less: Conditional PGGAN-based Data Augmentation for Brain Metastases Detection Using Highly-Rough Annotation on MR Images", In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), 2019. pdf
ニューラルネットワークのモデル圧縮
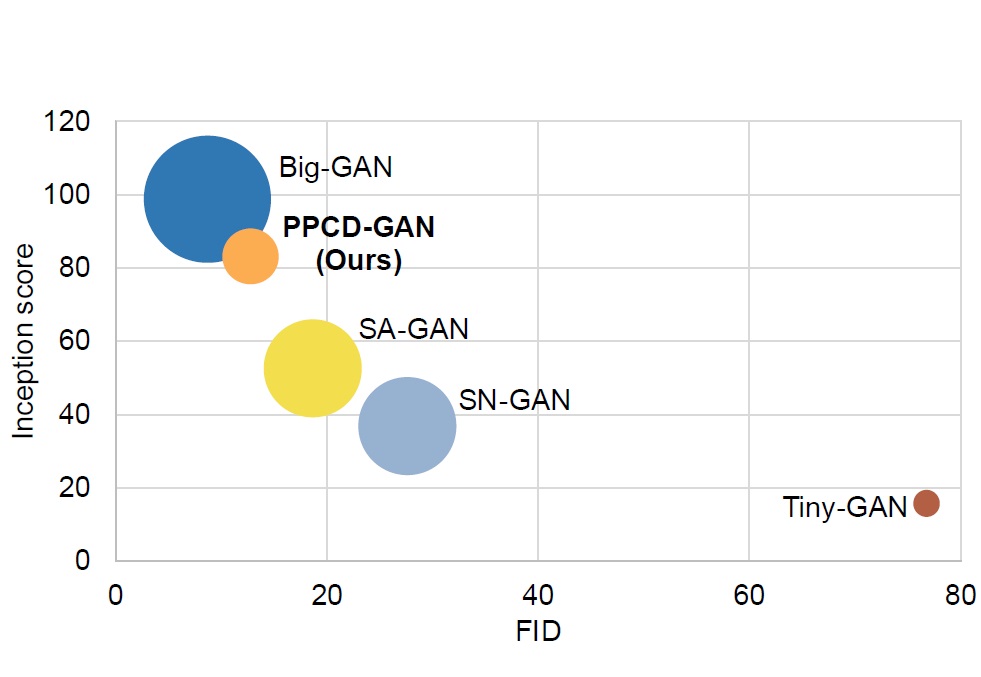
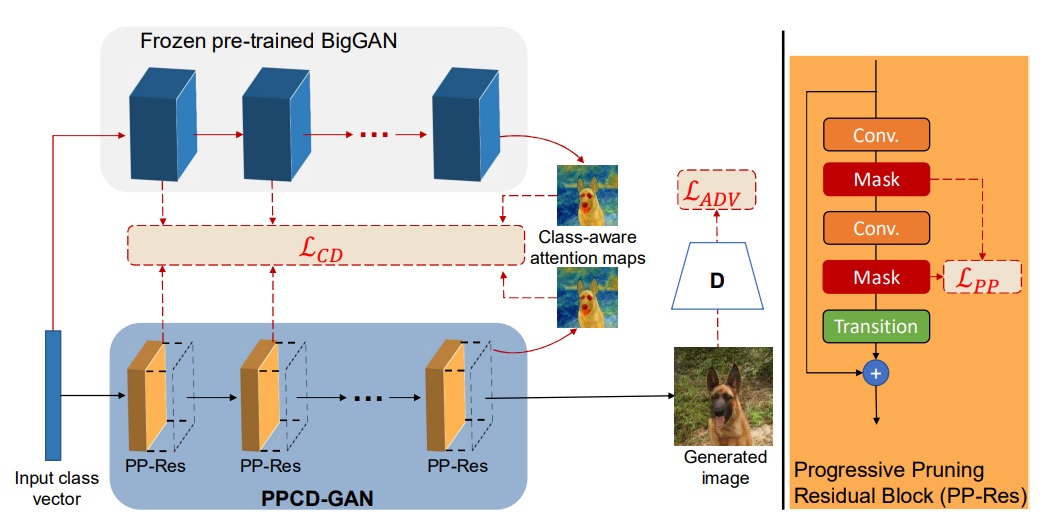
実用的な深層学習モデルの多くは非常に大規模なものであり、多大な計算コストを要します。モデルの性能を落とさずに容量を圧縮することができれば、例えばエッジデバイスなど計算資源が限定的な環境で実装することが可能となり、幅広い応用先の開拓へつながることが期待されます。 研究室では、プルーニングや蒸留、量子化などの技術を駆使し、さまざまなニューラルネットワークのモデル圧縮を行う研究を進めています。特に顕著な成果として、ベクトル量子化に基づく圧縮において離散コードと基底ベクトルをニューラルモデルの中で同時に学習する手法を提案しており、 当該手法を適用した機械翻訳の評価実験では、翻訳精度を落とすことなく単語ベクトルに必要な容量を94%〜99%圧縮できることが示されました。
- Duc Minh Vo et al., "PPCD-GAN: Progressive Pruning and Class-Aware Distillation for Large-Scale Conditional GANs Compression", Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), pp.2436-2444, 2022. pdf
- Raphael Shu and Hideki Nakayama, "Compressing Word Embeddings via Deep Compositional Code Learning", International Conference on Learning Representations (ICLR), 2018. pdf
- 朱中元, 中山英樹, "深層コード学習による単語分散表現の圧縮", 言語処理学会第24回年次大会, 2018. pdf (最優秀賞)
ラベルノイズに頑健な学習
機械学習の基本はラベル付きデータを用いた教師あり学習であり、ラベル付きデータをできるだけ多く準備することが性能を出すための最も素直なアプローチです。 しかしながら、質の良いラベル付きデータの作成は非常に高コストであり、データセットの規模やタスクの難易度が増すほど、ラベル付けの誤りが発生しやすくなります。 現実に、ImageNetなど研究分野で広く用いられているデータセットにも、多くのラベル誤りが混入していることが分かっています。
我々は、誤ったラベルに対して頑健な機械学習手法の開発に取り組んできました。さらに、これを半教師あり学習の枠組みも含め一般化する試みも行っています。
- Ryuichiro Hataya and Hideki Nakayama, "LOL: Learning to Optimize Loss Switching Under Label Noise", Proceedings of the 26th IEEE International Conference on Image Processing (ICIP), 2019.
- Ryuichiro Hataya and Hideki Nakayama, "Unifying Semi-Supervised and Robust Learning by Mixup", 2nd Learning from Limited Labeled Data (LLD) Workshop at ICLR 2019, 2019. pdf