Natural language processing
Sequence generation and machine translation
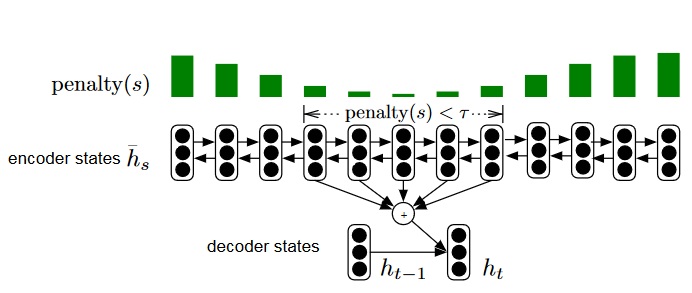
Recent advance of neural network enabled it to generate meaningful sequences. Neural-based sequence generation models can be applied to many Natural Language Processing tasks, such as machine translation, summarization and conversation generation. In this research, we try to increase the capability and performance os sequence generation models. For example, in order to prevent the model to generate a outrageous sentence in machine translation, we enhanced the decoding algorithm to search for a candidate with low Bayes risk (https://arxiv.org/abs/1704.03169). We are also rethinking the design of current architecture, so that the models receive fewer restrictions when generating sequences.
- Raphael Shu, Jason Lee, Hideki Nakayama, Kyunghyun Cho,"Latent-Variable Non-Autoregressive Neural Machine Translation with Deterministic Inference using a Delta Posterior", In Proceedings of AAAI, 2020.
- Raphael Shu, Hideki Nakayama, Kyunghyun Cho, "Generating Diverse Translations with Sentence Codes", In Proceedings of ACL, pp.1823–1827, 2019. pdf
- Raphael Shu, Hideki Nakayama, "Improving Beam Search by Removing Monotonic Constraint for Neural Machine Translation", In Proceedings of ACL, pp.339–344, 2018. pdf
- Raphael Shu, Hideki Nakayama, "Later-stage Minimum Bayes-Risk Decoding for Neural Machine Translation", arXiv, 2017. pdf
- Raphael Shu, Hideki Nakayama, "An Empirical Study of Adequate Vision Span for Attention-Based Neural Machine Translation", ACL Workshop on Neural Machine Translation, 2017. pdf (Outstanding Paper Award)
Discourse parsing

Natural language text is generally coherent and can be analyzed as discourse structures. Discourse parsing aims to uncover discourse structures automatically for given text and has been proven to be useul in various NLP applications. Despite the promising progress achieved in recent decades, discourse parsing still remains a significant challenge in NLP. The difficulty is due in part to shortage and low reliability of hand-annotated discourse structures. We tackle these problems by introducing unsupervised algorithms for discourse parsing, which induces discourse structures for given text without relying on manually annotated structures.
- Noriki Nishida and Hideki Nakayama, "Unsupervised Discourse Constituency Parsing Using Viterbi EM", Transactions of the Association for Computational Linguistics, Vol.8, pp.215-230, 2020. pdf
- Noriki Nishida, Hideki Nakayama, "Coherence Modeling Improves Implicit Discourse Relation Recognition", In Proceedings of the 19th Annual Meeting of the Special Interest Group on Discourse and Dialogue, 2018. pdf
Word representation learning
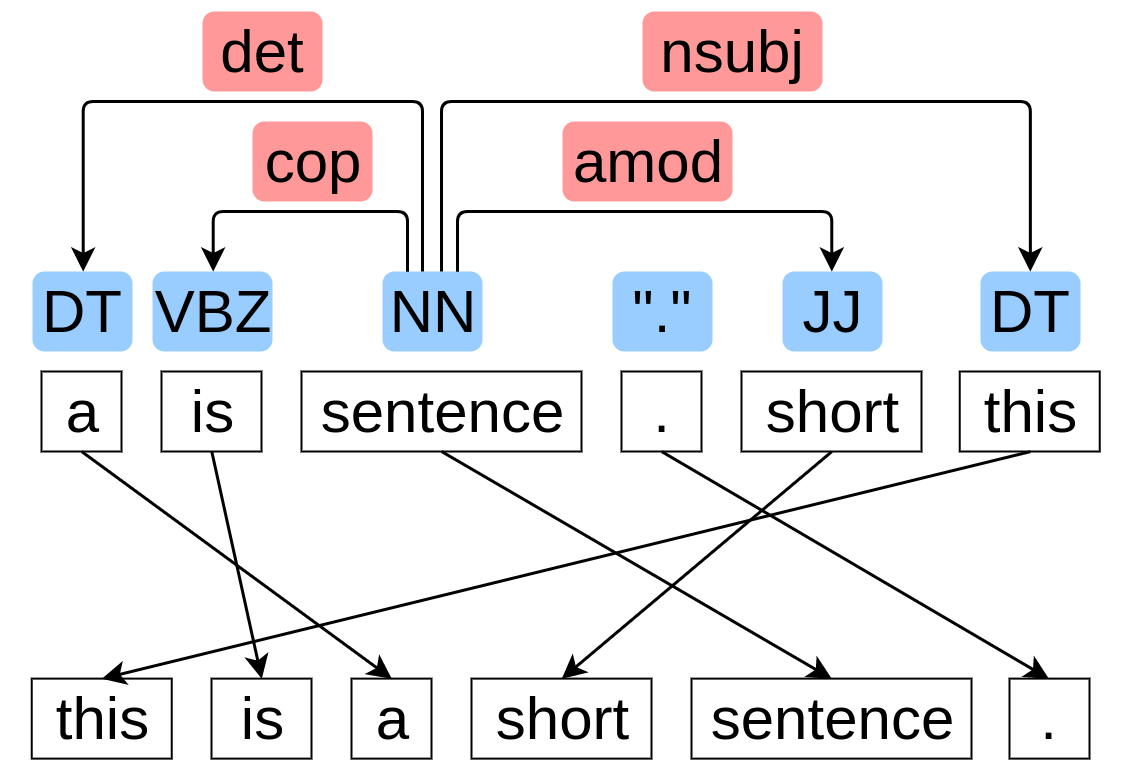
The research question we explore in this paper is how to learn syntactically plausible word representations without using human annotations. Our core idea is that word ordering tests, or linearization, can be an effective task for obtaining syntactic knowledge about words. To verify this hypothesis, we develop a neural network model that explicitly learns to recover correct word order while implicitly acquiring word embeddings capturing syntactic information. We evaluate the word embeddings produced by the proposed method on syntax-related tasks such as part-of-speech tagging and dependency parsing. The experimental results demonstrate that the proposed method consistently outperforms both order-insensitive and order-sensitive baselines on these tasks.
- Noriki Nishida, Hideki Nakayama, "Word Ordering as Unsupervised Learning Towards Syntactically Plausible Word Representations", International Joint Conference on Natural Language Processing, 2017. pdf