
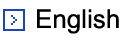
自然言語処理
当研究室では、自然言語処理の研究にも数多く取り組んできました。特に、機械翻訳、物語生成など、テキスト生成に関連するテーマで多くの成果を得ています。 テキスト生成は、近年の大規模言語モデル(LLM)の登場によりブレークスルーを迎えており、非常にエキサイティングな研究分野になっています。 我々は、LLM自体の学習や効率のよい利用方法の研究に加え、知識グラフ等の明示的な知識表現との融合による説明性や可制御性の向上などを狙った研究を進めています。 また、言語以外の情報も積極的に活用するマルチモーダル自然言語処理を特に得意な研究領域としています。
対話応答

汎用的な対話応答システムの実現は、自然言語処理のみならず人工知能全体における究極的な目標の一つといっても過言ではないでしょう。
近年の大規模言語モデル(LLM)の発達により、対話応答システムは驚異的な進歩を遂げましたが、依然として多くの問題を抱えています。
例えば、LLMは多くの場合内包する知識がブラックボックスであり、明示的に知識を追加・削除したり、不適切なバイアスを修正することが難しいことが知られています。
また、現状の対話システムでは言語以外のマルチモーダル情報の扱いが十分に考慮されていません。
研究室では、これらの問題を踏まえ、明示的な知識表現とのハイブリッドによる対話システムの個人適応や、マルチモーダル対話といった挑戦的な課題に取り組んでいます。
- Yi-Pei Chen et al., "LED: A Dataset for Life Event Extraction from Dialogs", Findings of the Association for Computational Linguistics: EACL 2023, pp.384-398, 2023. pdf
- Yi-Pei Chen et al., "How do people talk about images? A study on open-domain conversations with images", Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) Student Research Workshop, pp.156-162, 2022. pdf
- Hisashi Kamezawa et al., "A Visually-grounded First-person Dialogue Dataset with Verbal and Non-verbal Responses", Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.3299-3310, 2020. pdf
物語生成

人工知能が、人間の小説家のように長大で創造的な物語を創り出すことは可能でしょうか。物語生成も、大規模言語モデルによって近年著しく進歩している研究分野ですが、やはりまだまだ人間の持つ創造性には及ばないと言えるでしょう。 また、そもそも我々人間にとっても、よい物語の基準は主観的で曖昧なものであるため、今一度物語とは何かを考え直す必要があるかもしれません。
研究室では、グラフ表現を用いた物語生成仮定の可視化や制御に関する研究や、物語の評価・分析や改善提案を自動的に行うためのデータセットとシステムの構築を行っています。
- Hong Chen et al., "StoryER: Automatic Story Evaluation via Ranking, Rating and Reasoning", Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.1739-1753, 2022. pdf
- Hong Chen et al., "GraphPlan: Story Generation by Planning with Event Graph", Proceedings of the 14th International Conference on Natural Language Generation (INLG), pp.377-386, 2021. pdf
- Hong Chen et al., "Commonsense Knowledge Aware Concept Selection for Diverse and Informative Visual Storytelling", Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI), pp.999-1008, 2021. pdf
機械翻訳

ニューラル機械翻訳は非常に優れた翻訳精度を達成するようになった一方で、依然として、計算コストが大きいこと、出力文の多様性確保が難しいこと、などの課題があります。 これらの課題を改善するために、文構造を考慮した潜在変数を活用した新しいニューラル機械翻訳のモデルを提案しています。具体的な例としては、非自己回帰型デコーダによる高速な翻訳や、潜在変数による条件付けモデルを用いた多様な翻訳などを実現しています。これらは、機械翻訳に限らず一般的なテキストやシーケンスの生成にも応用可能な技術です。 また、テキスト情報のみならず、画像などのマルチメディア情報を条件付けに活用するマルチモーダル機械翻訳の研究も進めています。
- Raphael Shu et al., "Latent-Variable Non-Autoregressive Neural Machine Translation with Deterministic Inference using a Delta Posterior", In Proceedings of AAAI, 2020.
- Tetsuro Nishihara et al., "Supervised Visual Attention for Multimodal Neural Machine Translation", Proceedings of the International Conference on Computational Linguistics (COLING), pp.4304-4314, 2020. pdf
- Raphael Shu et al., "Generating Diverse Translations with Sentence Codes", In Proceedings of ACL, pp.1823–1827, 2019. pdf
- 朱中元, 中山英樹, "Generating Syntactically Diverse Translations with Syntactic Codes", 言語処理学会第25回年次大会, 2019. pdf (最優秀賞)
- Raphael Shu and Hideki Nakayama, "Improving Beam Search by Removing Monotonic Constraint for Neural Machine Translation", In Proceedings of ACL, pp.339–344, 2018. pdf
- Raphael Shu and Hideki Nakayama, "An Empirical Study of Adequate Vision Span for Attention-Based Neural Machine Translation", ACL Workshop on Neural Machine Translation, 2017. pdf (Outstanding Paper Award)
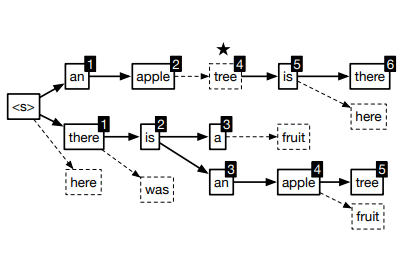
テキスト生成応用

テキスト生成技術を応用した先進的なアプリケーションの提案を積極的に行っており、そのための手法とデータセットの開発を両輪で進めています。 これまでに取り組んだ例として、GitHub等のソフトウェア開発プラットフォームにおいてコミットログを要約し自動的にリリースノートを生成する研究や、学術的な論文の執筆支援を行う研究が挙げられます。
- Hisashi Kamezawa et al., "RNSum: A Large-Scale Dataset for Automatic Release Note Generation via Commit Logs Summarization", Proceedings of the Association for Computational Linguistics (ACL), pp.8718–8735, 2022. pdf
- Hong Chen, Hiroya Takamura, and Hideki Nakayama, "SciXGen: A Scientific Paper Dataset for Context-Aware Text Generation", Findings of the Association for Computational Linguistics: EMNLP 2021, pp.1483-1492, 2021. pdf
談話構造解析

一貫性のある文章において、その言語単位 (節や文、段落など) は統語的、意味的、論理的に相互結合しており、孤立したテキスト領域は存在しません。そのような文章の一貫性は談話構造として表現されます。談話構造解析とは、入力文章の談話構造を計算機によって自動的に同定する技術であり、様々な応用技術においてその有用性が確認されています。近年の技術的進歩にもかかわらず、談話構造解析は依然として困難なタスクのままです。その原因としては、人手による談話構造のアノテーションが高コストであることと、その信頼性が低いことが挙げられます。そこで、人手による談話構造アノテーションに依らない談話構造解析を実現するために、我々は談話構造解析のための教師なしアルゴリズムを開発しています。
- Noriki Nishida and Hideki Nakayama, "Unsupervised Discourse Constituency Parsing Using Viterbi EM", Transactions of the Association for Computational Linguistics, Vol.8, pp.215-230, 2020. pdf
- Noriki Nishida and Hideki Nakayama, "Coherence Modeling Improves Implicit Discourse Relation Recognition", In Proceedings of the 19th Annual Meeting of the Special Interest Group on Discourse and Dialogue, 2018. pdf
単語表現の学習
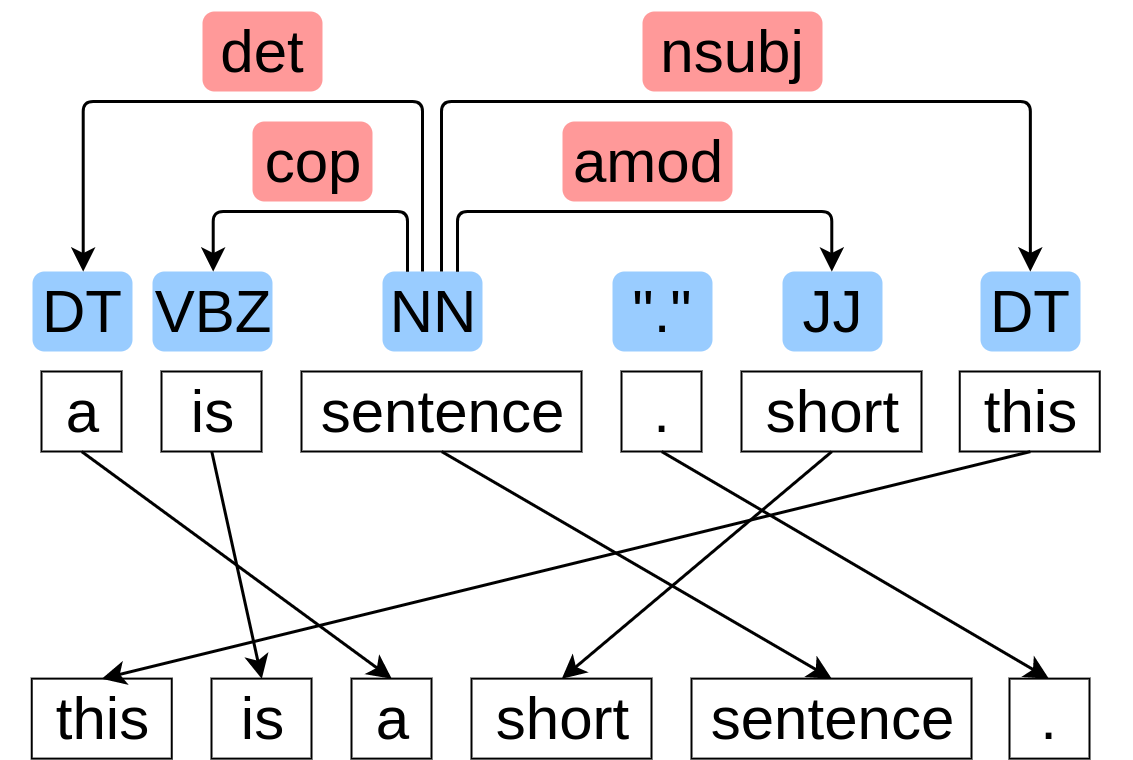
この研究では、統語的に妥当な単語ベクトル表現の獲得を目指し、そのための教師なし学習手法を提案しました。基本アイデアは、語順情報はその言語の文法と深く関わっており、特に単語の並び替えテストが単語に関する統語知識を獲得するのに有効であるというものです。この仮説を検証するために、単語並び替え問題を学習しながら、統語情報をとらえた単語ベクトル表現を間接的に学習するニューラルネットワークを提案しました。提案手法によって得られた単語表現を品詞タグ付けや依存構造解析などの統語知識と関連するタスクにおいて評価し、提案手法が語順を考慮しない、または考慮している既存手法よりもより効果的に、統語情報に焦点を当てた単語ベクトルを学習していることを示しました。
- Noriki Nishida, Hideki Nakayama, "Word Ordering as Unsupervised Learning Towards Syntactically Plausible Word Representations", In Proceedings of the 8th International Joint Conference on Natural Language Processing, 2017. pdf
- 西田典起, 中山英樹, "Learning Syntactically Plausible Word Representations by Solving Word Ordering", 人工知能学会全国大会, 2017.
(全国大会優秀賞)