Image Recognition and Understanding
Large-scale generic image recognition and feature representation

We are developing a computer vision system that can distinguish tens of thousands of objects and scenes. To realize this, we need to train the system with an extremely large training dataset that consists of tens of millions of examples. Visual learning at this scale requires many technologies in both software and hardware, including efficient feature extraction and machine learning methods, parallel computing with clusters and GPUs.
- Hideki Nakayama, "Aggregating descriptors with local Gaussian metrics", NIPS 2012 Workshop on Large Scale Visual Recognition and Retrieval, 2012. pdf
- Hideki Nakayama, Tatsuya Harada, and Yasuo Kuniyoshi,"Global Gaussian Approach for Scene Categorization Using Information Geometry", In Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), 2010. pdf
- Hideki Nakayama, Tatsuya Harada, and Yasuo Kuniyoshi, "Evaluation of Dimensionality Reduction Methods for Image Auto-Annotation", In Proceedings of British Machine Vision Conference (BMVC), 2010. pdf
Visual relationship recognition
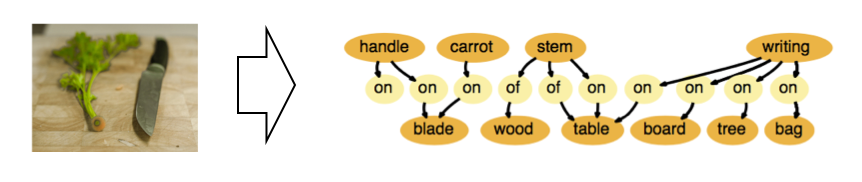
Visual relationship recognition is a task of recognizing multiple objects and their relationships given visual information such as an image or a video. One of the fundamental difficulties of this task is the class-number scalability problem, which the number of possible relationships we need to consider causes combination explosion. We developed a model that is able to perform such task sequentially. Furthermore, we aim to develop a model which can detect object relationships along with object regions and volumes in 3d space.
- Kento Masui, Akiyoshi Ochiai, Shintaro Yoshizawa and Hideki Nakayama, "Recurrent Visual Relationship Recognition with Triplet Unit", IEEE International Symposium on Multimedia (ISM), 2017. pdf
Medical Image Analysis
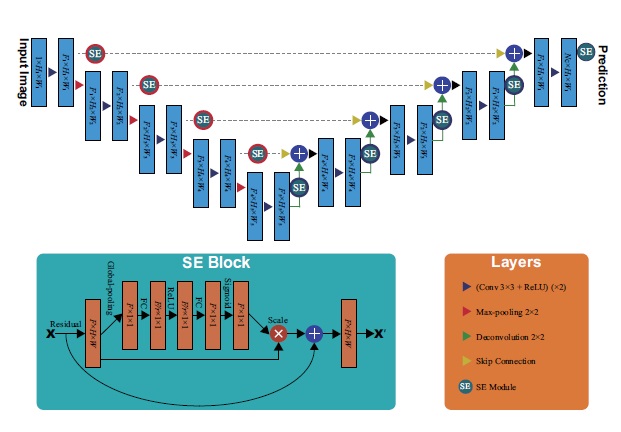
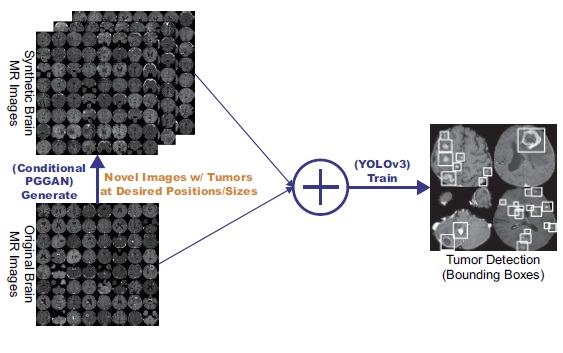
Accurate Computer-Assisted Diagnosis, associated with proper datawrangling, can alleviate the risk of overlooking the diagnosis in aclinical environment. However, it is not always possible to prepare sufficient amount of training data because of the rarity and privacy issues of medical images, and high annotation costs. To address this problem, we develop Data Augmentation (DA) techniques based on Generative Adversarial Networks (GANs) to synthesize additional training data to handle the small/fragmented medicalimaging datasets collected from various scanners. We also develop powerful CNN architectures that can efficiently handle multi-domain data collected from multiple institutions.
- Changhee Han et al., "Learning More with Less: Conditional PGGAN-based Data Augmentation for Brain Metastases Detection Using Highly-Rough Annotation on MR Images", In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), 2019. pdf
- Changhee Han et al., "Synthesizing Diverse Lung Nodules Wherever Massively: 3D Multi-Conditional GAN-based CT Image Augmentation for Object Detection", In Proceedings of the International Conference on 3D Vision (3DV), 2019. pdf
- Leonardo Rundo, Changhee Han et al., "USE-Net: incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets", Neurocomputing, Volume 365, Pages 31-43, 2019. pdf
Fine-grained visual categorization
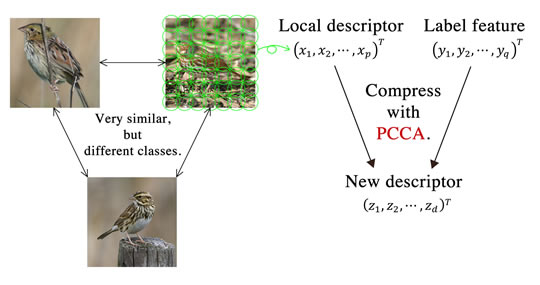
The goal of fine-grained visual categorization (FGVC) is to categorize conceptually (and thus visually) similar classes such as plant and animal species. Although the domain is fixed for specific applications (e.g., bird, dog, etc.), it is targeted to recognize hundreds of fine-grained categories, which goes far beyond typical human knowledge. However, FGVC is extremely challenging because of its high intra-class and low inter-class variations, and is thought to require new technologies.
We are developing a feature learning algorithm for FGVC, and have obtained promising results. We have got the 1st place out of 12 groups in the Plant Identification Task (NaturalBackground) of ImageCLEF 2013. Moreover, we achieved the 1st place in four out of five subtasks.
- Hideki Nakayama, "Augmenting descriptors for fine-grained visual categorization using polynomial embedding", IEEE International Conference on Multimedia & Expo (ICME), 2013. pdf
- Hideki Nakayama, "NLab-UTokyo at ImageCLEF 2013 Plant Identifitication Task", CLEF 2013 Working Notes, 2013. pdf
- Experimental Results on Fine-grained challenge 2013. link
Multilingual scene text reading in natural images
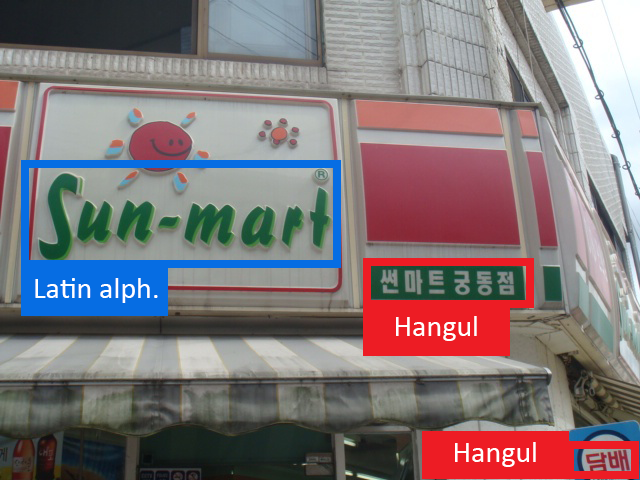
Owing to increasing globalization and mixing demographics, we encounter text in various writing systems in our everyday lives. The growth of such multilingual environments and the increasing interest in scene text (text in natural scene images) reading raises the need to recognize and distinguish between different scripts, such as Latin alphabet, Arabic script, and Chinese characters. Detecting the script used in a scene text allows us to perform multilingual scene text reading by using multiple script-specific text recognition models instead of using one large class-imbalanced model supporting recognition of thousands of characters in multiple scripts. By adopting this approach, we aim to improve the overall performance of multilingual scene text reading.
- Jan Zdenek, Hideki Nakayama, "Bag of Local Convolutional Triplets for Script Identification in Scene Text", International Conference on Document Analysis and Recognition (ICDAR), 2017.
- Jan Zdenek, Hideki Nakayama, "Script Identification using Bag-of-Words with Entropy-weighted Patches", JSAI, 2017. pdf