Hideki Nakayama's Page |
Large-scale image annotation
 To realize generic image recognition, the system needs to
learn an enormous amount of targets in the world and their visual
appearances. Therefore, visual knowledge acquisition using
massive amounts of web images has been studied recently,
and search-based methods are now flourishing in this research
field. However, in general, search process of such
methods are conducted using similarity measures based on
simple image features and suffer from the semantic gap.
To realize generic image recognition, the system needs to
learn an enormous amount of targets in the world and their visual
appearances. Therefore, visual knowledge acquisition using
massive amounts of web images has been studied recently,
and search-based methods are now flourishing in this research
field. However, in general, search process of such
methods are conducted using similarity measures based on
simple image features and suffer from the semantic gap.
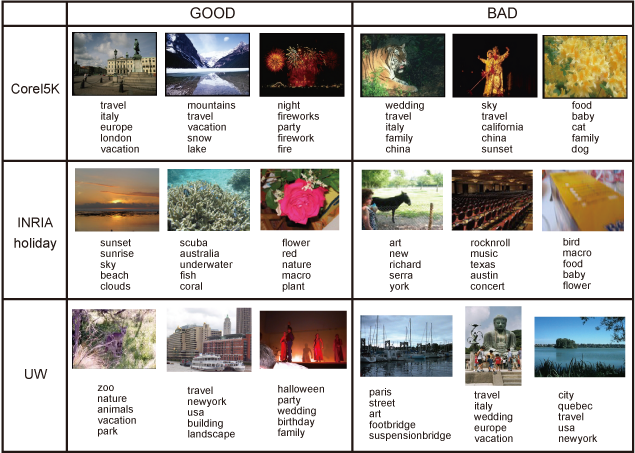
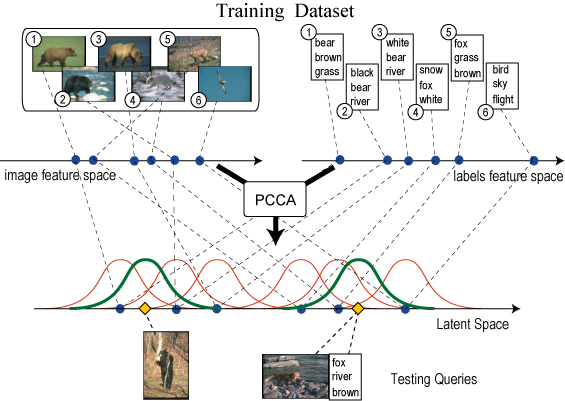
In this research, we propose a method of image annotation
and retrieval based on the new similarity measure, Canonical
Contextual Distance. This method effectively uses contexts
of images estimated from multiple labels and learns the
essential and discriminative latent space. Using the probabilistic
structure, our similarity measure can reflect both
appearance and semantics of samples. Because our learning
method is highly scalable, it is especially effective in a large
web-scale dataset.
We show the effectiveness of our
system using a large-scale dataset consisting of twelve million web images.
In addition, we participated in ImageNet Large Scale Visual Recognition Challenge and got the 3rd place.
Publications
- Hideki Nakayama, Tatsuya Harada, and Yasuo Kuniyoshi,
"Canonical Contextual Distance for Large-Scale Image Annotation and Retrieval," the 1st ACM International Workshop on Large-Scale Multimedia Mining and Retrieval (LS-MMRM), pp.3-10, 2009. link - Hideki Nakayama, Tatsuya Harada, and Yasuo Kuniyoshi,
"Evaluation of Dimensionality Reduction Methods for Image Auto-Annotation," British Machine Vision Conference (BMVC), 2010. link
- Object Recognition Server (not in operation now)
Image feature representation
 Local features provide powerful cues for generic image
recognition. An image is represented by a “bag” of local
features, which form a probabilistic distribution in the
feature space. The problem is how to exploit the distributions
efficiently. One of the most successful approaches is
the bag-of-keypoints scheme, which can be interpreted as
sparse sampling of high-level statistics, in the sense that it
describes a complex structure of a local feature distribution
using a relatively small number of parameters.
Local features provide powerful cues for generic image
recognition. An image is represented by a “bag” of local
features, which form a probabilistic distribution in the
feature space. The problem is how to exploit the distributions
efficiently. One of the most successful approaches is
the bag-of-keypoints scheme, which can be interpreted as
sparse sampling of high-level statistics, in the sense that it
describes a complex structure of a local feature distribution
using a relatively small number of parameters.
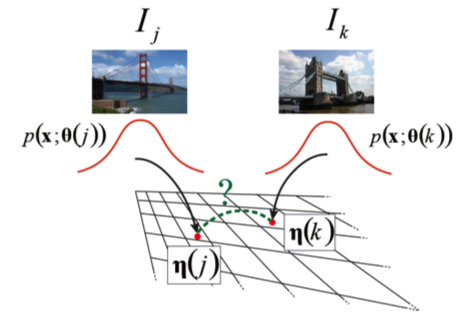
In this research,we propose the opposite approach, dense sampling of
low-level statistics. A distribution is represented by a Gaussian
in the entire feature space. We define some similarity
measures of the distributions based on an information geometry
framework and show how this conceptually simple
approach can provide a satisfactory performance, comparable
to the bag-of-keypoints for scene classification tasks.
Furthermore, because our method and bag-of-keypoints illustrate
different statistical points, we can further improve
classification performance by using both of them in kernels.
Publications
- Hideki Nakayama, Tatsuya Harada, and Yasuo Kuniyoshi,
"Global Gaussian Approach for Scene Categorization Using Information Geometry," IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010. link - Hideki Nakayama, Tatsuya Harada, and Yasuo Kuniyoshi,
"Dense Sampling Low-Level Statistics of Local Features," ACM International Conference on Image and Video Retrieval (CIVR), 2009. link
AI Goggles
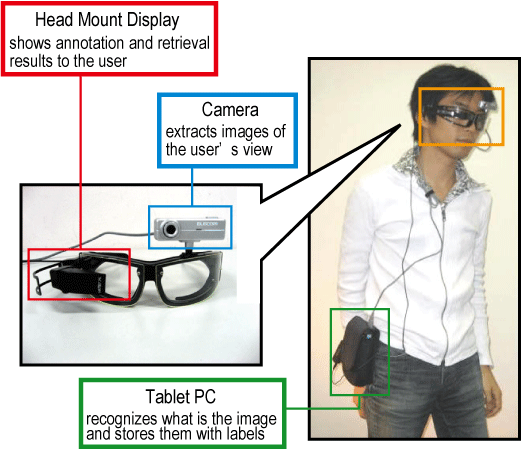
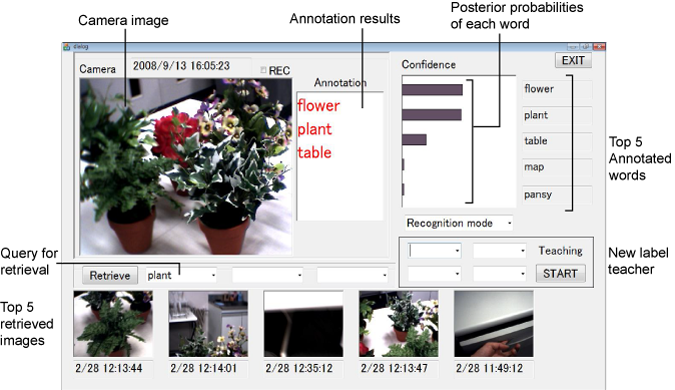
We present the AI Goggles system, which can instantly describe objects and scenes in the real world and retrieve visual memories about them using keywords input by the users. This is a stand-alone wearable system working on a tiny mobile computer (Core2Duo, 1.2GHz). Also, the system can quickly learn unknown objects and scenes by teaching and learn to label and retrieve them on site, without loss of recognition ability for previously learnt ones. This systen can serve as a visual and memory assistive man-machine user interface.
Publications
- Hideki Nakayama, Tatsuya Harada, and Yasuo Kuniyoshi,
"AI Goggles: Real-time Description and Retrieval in the Real World with Online Learning," Canadian Conference on Computer and Robot Vision (CRV 2009), pp.184-191, 2009.