
マルチモーダル
深層学習の普及により、人工知能に関わるさまざまな分野の融合が急速に進んでいます。人間や動物が五感情報を活用しながら日々生活しているように、マルチモーダル情報の利用は汎用的な人工知能の実現にとっても必要不可欠であると言えます。 研究室では、画像認識と自然言語処理のそれぞれのグループが最前線で活躍していることから、両者の横断的な研究分野であるVision and Languageを非常に得意な領域としています。 また、近年では音声や脳信号などもスコープに加え、さらに幅広いマルチモーダル情報処理の開拓に積極的に取り組んでいます。
画像・動画像キャプショニング
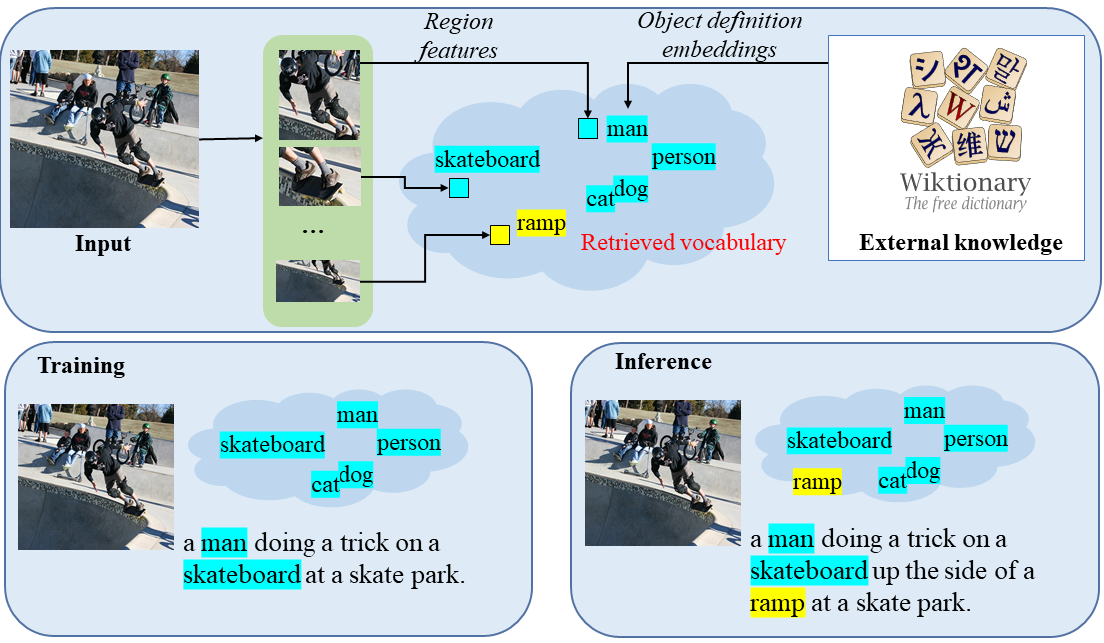

画像キャプショニング(説明文生成)とは、画像の内容を自然言語で説明するタスクであり、いわゆるVision and Languageの代表的な研究分野の一つです。研究室では画像キャプショニングの研究に長く取り組んでおり、特に動画像のキャプショニングに関して先駆的な成果を挙げています。 最近では、未知物体に関するキャプショニングや、与えられた画像の未来のイベントを予測して記述する予測キャプショニングなど、より先進的かつ挑戦的な問題を提案して取り組んでいます。
- Vo et al., "NOC-REK: Novel Object Captioning with Retrieved Vocabulary from External Knowledge", IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.17979-17987, 2022. pdf
- Natsuda Laokulrat, Naoaki Okazaki, Hideki Nakayama, "Incorporating Semantic Attention in Video Description Generation", Internationl Conference on Language Resources and Evaluation (LREC), pp.3011-3017, 2018. pdf
- Natsuda Laokulrat et al., "Generating Video Description using Sequence-to-sequence Model with Temporal Attention", International Conference on Computational Linguistics (COLING), 2016. pdf
画像物語生成

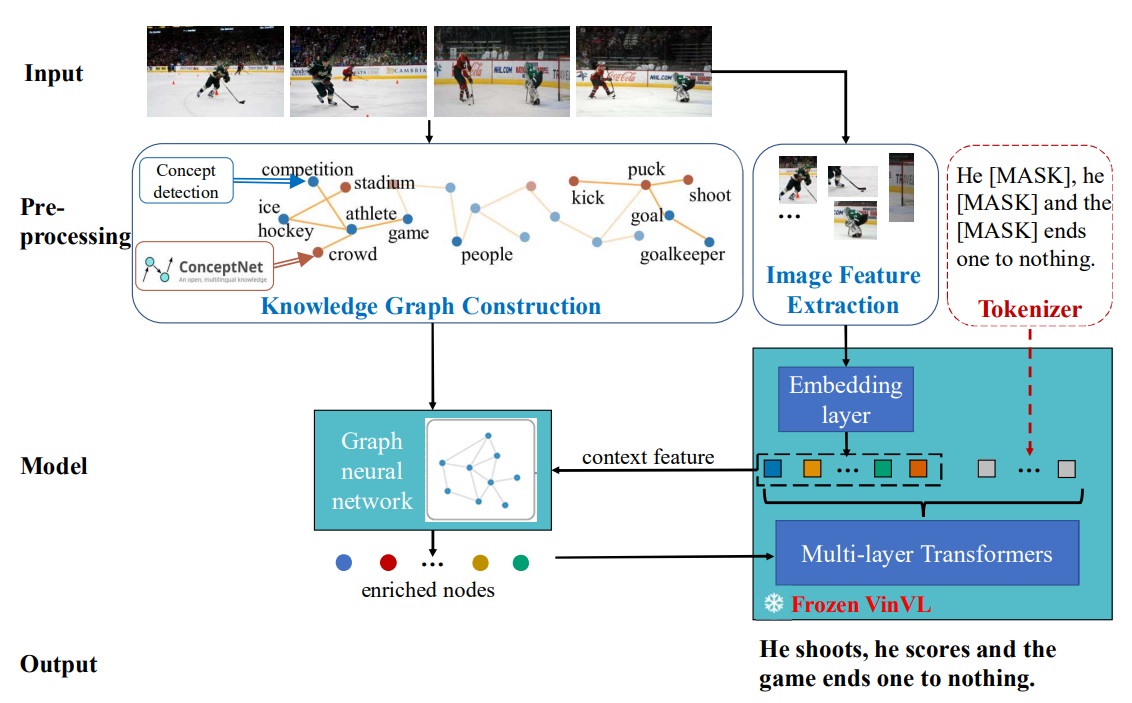
画像物語生成とは、時系列に沿った複数の画像を種として物語を生成するタスクです。画像キャプショニングのように、単に与えられた画像の内容を説明すればよいわけではなく、画像から想像を膨らませながら全体として辻褄のあった面白い物語を作ることが目的となります。 つまり、画像キャプショニングと物語生成の横断的なタスクであるといえるでしょう。 我々は、画像から検出される物体やイベントを出発点とし、外部の知識グラフを探索することで関連する概念を取得し、物語生成に役立てる枠組みを提案しています。知識グラフ上の探索により、アルゴリズムは発想の幅を広げることができるのみならず、推論の過程をより明確化することが可能となります。 このようなトップダウンな知識データベースとの接続は、帰納と演繹の融合という人工知能の大きなテーマから見ても興味深いものであり、他の研究への応用にも力を入れています。
- Vo et al., "A-CAP: Anticipation Captioning with Commonsense Knowledge", IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.10824-10833, 2023. pdf
- Hong Chen et al., "Commonsense Knowledge Aware Concept Selection for Diverse and Informative Visual Storytelling", Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI), pp.999-1008, 2021. pdf
物語可視化
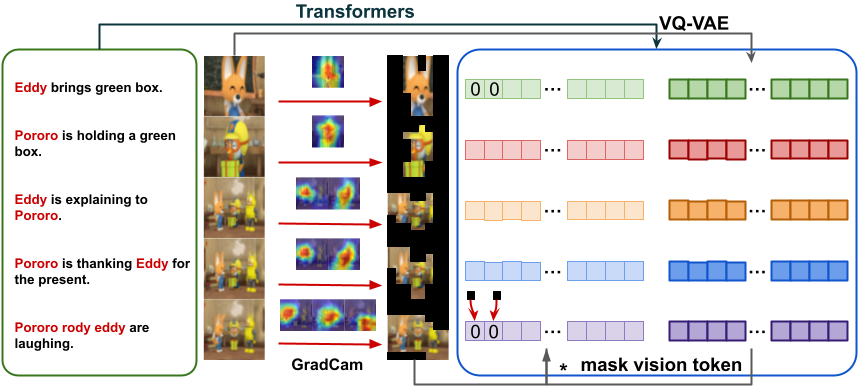

画像物語生成とは逆に、与えられた物語テキストを表す画像列を時系列に沿って生成するタスクです。与えた筋に沿った4コマ漫画を作ると言えばイメージしやすいでしょうか。 画像生成は近年驚異的な進歩を遂げていますが、時系列のように依存関係がある複数の画像を整合性のある形で生成することはまだ困難です。 研究室では、物語生成の成果から得られた知見を応用し、物語可視化においてもあらかじめ全体の計画を立て重要部分のみを先に生成することで、複数画像の整合性を保つアプローチを提案しています。 また、生成した画像(キーフレーム)を階層的に補間していくことで、最終的には長時間の動画像生成を実現することを目指しています。
- Hong Chen et al., "Character-Centric Story Visualization via Visual Planning and Token Alignment", Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.8259-8272, 2022. pdf
マルチモーダル機械翻訳
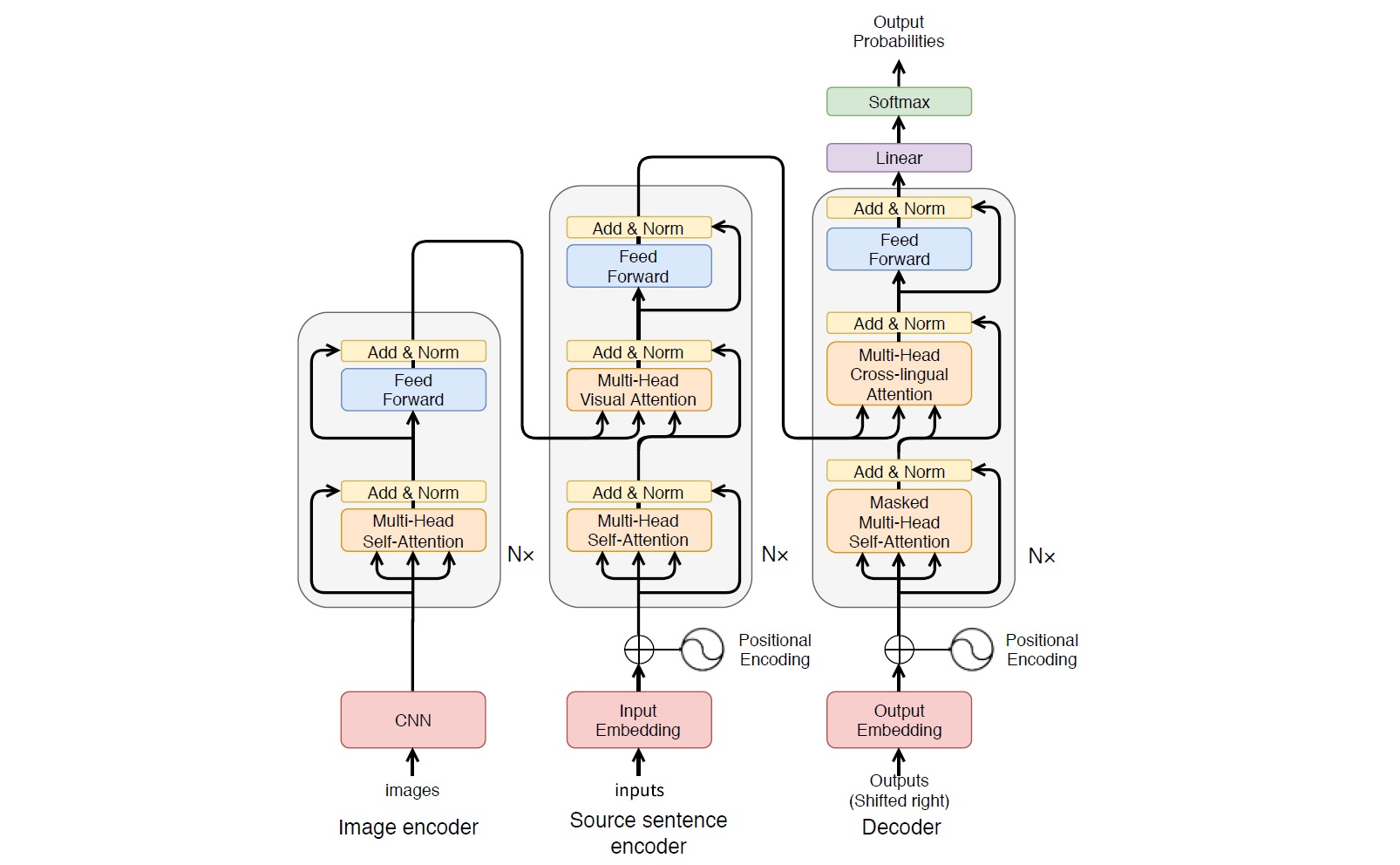
一般的な機械翻訳はテキストの入出力変換(元言語→目的言語)として定式化されますが、対象領域によってはテキスト以外の付加的な情報が得られる場合があります。 例えば、新聞記事やWebのブログ記事などでは、内容に関連した写真が記事に含まれていることが多いでしょう。このような画像情報は、テキスト部分の翻訳において有用な手掛かりを与えてくれることが期待できます。
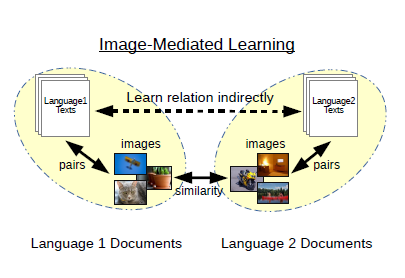
研究室では、日英マルチモーダル機械翻訳のためのデータセット開発やコンペティションの開催を行うなど、本分野における先導的な活動を行っています。 また、単に画像を付加的な入力として用いるだけではなく、画像をハブとして異言語間の共通の埋め込み空間を間接的に学習することで、機械翻訳や言語横断文書検索システムを一切のパラレルコーパスなしに学習する手法も提案しています。
- Tetsuro Nishihara et al., "Supervised Visual Attention for Multimodal Neural Machine Translation", Proceedings of the International Conference on Computational Linguistics (COLING), pp.4304-4314, 2020. pdf
- Hiroki Takushima et al., "Multimodal Neural Machine Translation Using CNN and Transformer Encoder", Proceedings of the 20th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing), 2019. pdf
- Hideki Nakayama, Noriki Nishida, "Zero-resource Machine Translation by Multimodal Encoder-decoder Network with Multimedia Pivot", Machine Translation, Volume 31, Issue 1-2, pp.49-64, 2017. pdf
- Ruka Funaki, Hideki Nakayama, "Image-mediated learning for zero-shot cross-lingual document retrieval", Empirical Methods in Natural Language Processing (EMNLP), 2015. pdf
- Pascal1K+jp データセット
マルチモーダル対話

人間は、対話において言葉のみならず、視覚・聴覚などさまざまな情報を通じ文脈を共有しながら意思疎通を行っています。 ロボットなどの実世界で活動するエージェントが人間とコミュニケーションをとるためには、このようなマルチモーダル情報を活用した対話の実現が重要になると考えられます。 我々はこのようなシナリオを踏まえ、対話相手の視線情報をアノテーションした一人称視点画像を加えた対話データセットを構築しました。画像や視線情報は、発話内容の曖昧性を解消し対話の質向上に大きく貢献することが示されています。
- Yi-Pei Chen et al., "How do people talk about images? A study on open-domain conversations with images", Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) Student Research Workshop, pp.156-162, 2022. pdf
- Hisashi Kamezawa et al., "A Visually-grounded First-person Dialogue Dataset with Verbal and Non-verbal Responses", Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.3299-3310, 2020. pdf
ビジュアルグラウンディング
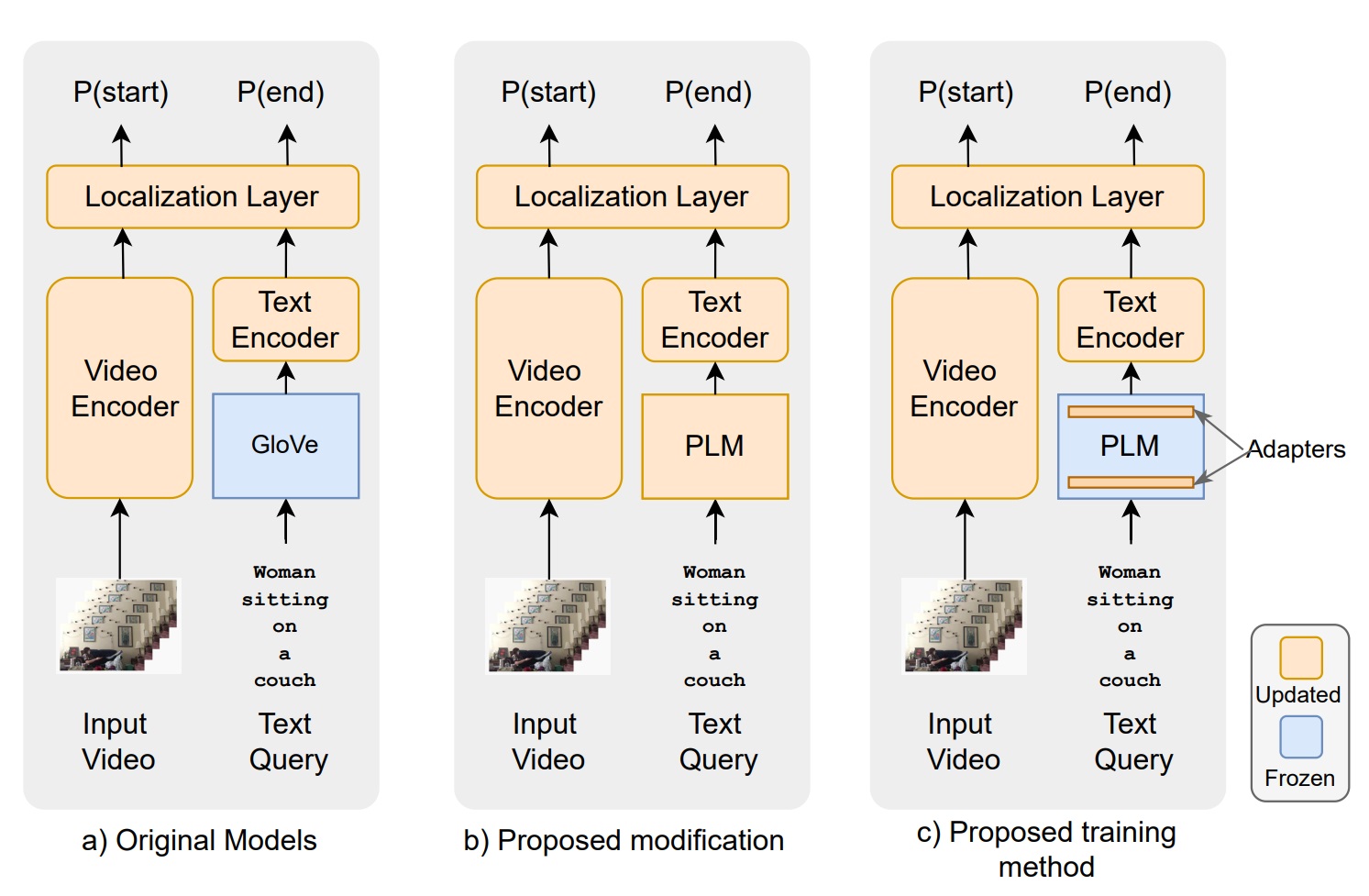

画像と言語のグラウンディング(記号接地)は、コンピュータビジョンと自然言語処理を接続するための根幹と呼べる課題です。 CLIP等の基盤モデルは大量の画像・テキストペアデータを用いた学習により両者を横断する埋め込み空間を導出していますが、基本的には画像全体と文全体のラフなアラインメントしかできていません。 我々は、より時空間的に細かい粒度のグラウンディングを行うための学習手法やデータセットの開発を行っています。また、大規模言語モデルを効率よくグラウンディングへ用いるための転移学習法についても研究しています。
- Erica Kido Shimomoto et al., "Towards Parameter-Efficient Integration of Pre-Trained Language Models In Temporal Video Grounding", Findings of the Association for Computational Linguistics: ACL 2023, 2023. pdf
- Hideki Nakayama et al., "A Visually-Grounded Parallel Corpus with Phrase-to-Region Linking", Proceedings of the 25th International Conference on Language Resources and Evaluation (LREC), pp.4204-4210, 2020. pdf