Open-world Image Recognition
Typical machine learning based systems only accept pre-defined concepts available in given training datasets. However, in real world, there an infinite number of unknown classes and new ones would appear every day. Moreover, even for the known classes, their distributions can change dynamically. In such an open-world setup, it is important to catch up dynamic changes in knowledge, and flexibly aquire new things as autonomously as possible.
We are currently working on domain adaptation, object discovery, and human-in-the-loop approach as we believe they are the keys to realize such open-world intelligent systems.
Cosegmentation for object discovery
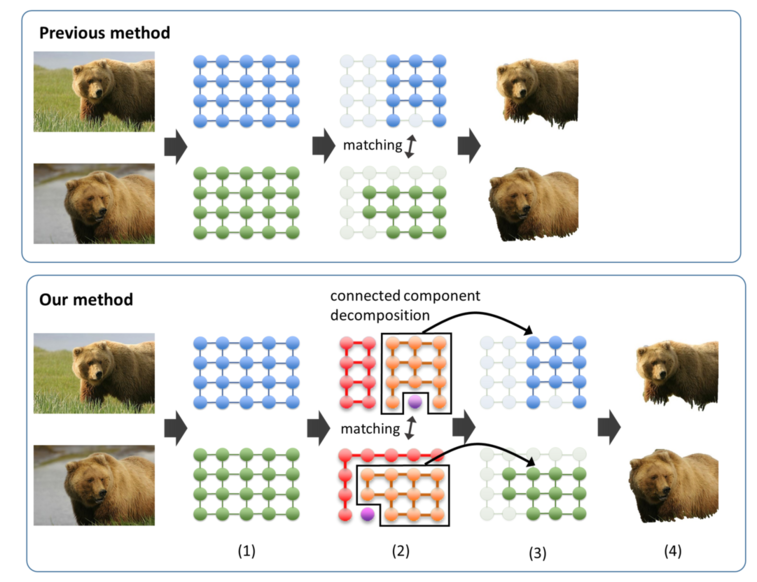
Cosegmentation is the task of segmentating a common object from multiple images. Recenty, constructing visual knowledge base for the image recognition from Internet data is studied actively. Most of those Internet data include miscellaneous background that becomes a noise. Cosegmentation algorithms can be used a method for the noise reduction. In our lab, we are developing a novel unsupervised cosegmentation algorithm based on graph matching.
- Hong Chen, Yifei Huang, Hideki Nakayama, "Semantic Aware Attention Based Deep Object Co-segmentation","Unsupervised Cosegmentation Based on Global Graph Matching", In Proceedings of ACCV, pp.435-450, 2018. pdf
- Takanori Tamanaha, Hideki Nakayama, "Unsupervised Cosegmentation Based on Global Graph Matching", In Proceedings of ACM International Conference on Multimedia, 2015. pdf
First-person vision interface
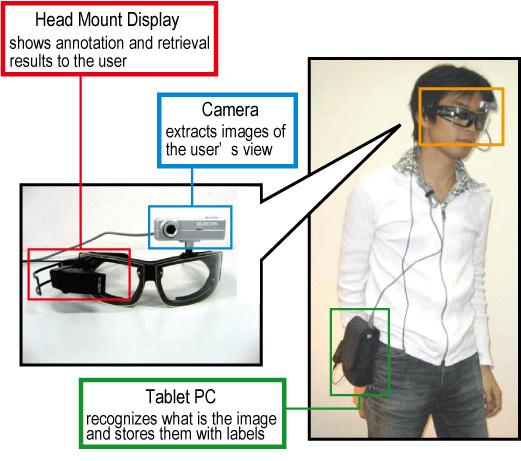
We focus on developing new interface and application using first-person vision. This system can instantly describe objects and scenes in the real world and retrieve visual memories about them using keywords input by the users. Also, the system can quickly learn unknown objects and scenes by teaching and learn to label and retrieve them on site, without loss of recognition ability for previously learnt ones. This systen can serve as a visual and memory assistive man-machine user interface.
Our current interest is the knowledge transfer from web data to implement more practical visual knowledge into the system.
- Hideki Nakayama, Tatsuya Harada, and Yasuo Kuniyoshi, "AI Goggles: Real-time Description and Retrieval in the Real World with Online Learning", In Proceedings of Canadian Conference on Computer and Robot Vision (CRV), pp.184-191, 2009. pdf
Multi-modal domain adaptation using lifelog data

Generally, we need a large-scale labeled dataset to train powerful recognition systems. In reality, however, manually labeling data is quite high-cost and not always practical. Domain adaptation is a technique to transfer learned from labeled data in other domain (e.g., Web dataset) to target domain where labeled data is scarce. In our lab, we propose a new approach that transfers knowledge more efficiently by utilizing not only images but also other modalities. We use various sensory inputs in lifelog data obtained together with images to make the target space more discriminative.
- Masaya Okamoto, Hideki Nakayama, "Unsupervised visual domain adaptation using auxiliary information in target domain", In Proceedings of IEEE International Symposium on Multimedia (ISM), 2014. pdf